Apache Hive 主要是讓不會寫 MapReduce 程式 的 SQL人員,可以透過所熟悉的 SQL 語法分析大數據資料. 雖然 Hive 的語法和 SQL 可以說是 90%以上都相同,但是基於目前的設計架構,Hive 無法像關聯式資料庫可以快速查詢資料,雖然如此,但相信往後的版本會一一克服的!
Apache Hive 運作架構圖
在上圖中, Hive 資料表的 Schema (MetaStore) 是儲存在本機或網路型關聯式資料庫 (RDBMS), 而資料表的資料則是存在 HDFS 分散檔案系統, 資料分析會先將你所撰寫的 HiveQL 編譯成 MapReduce 程式, 然後交由 YARN 分散運算系統執行
啟動 Hadoop 電戰系統 (HDFS,YARN)
1. 啟動 Hadoop 所有貨櫃主機
$ dkstart a
2. 啟動 HDFS 分散檔案系統
$ starthdfs a
3. 啟動 YARN 分散運算系統
$ startyarn a
資料科學家上工
1. 登入 Hadoop Client 貨櫃主機
$ ssh ds01@cla01
2. 檢視 Hive 版本
$ hive --version
Hive 1.2.1
Subversion git://localhost.localdomain/home/sush/dev/hive.git -r 243e7c1ac39cb7ac8b65c5bc6988f5cc3162f558
Compiled by sush on Fri Jun 19 02:03:48 PDT 2015
From source with checksum ab480aca41b24a9c3751b8c023338231
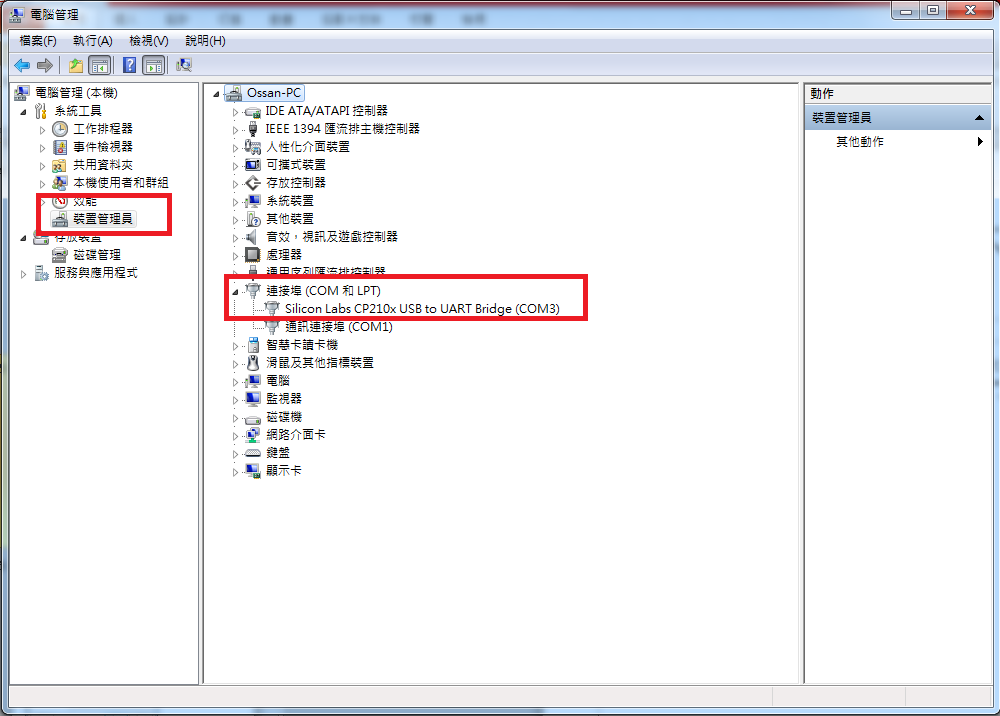
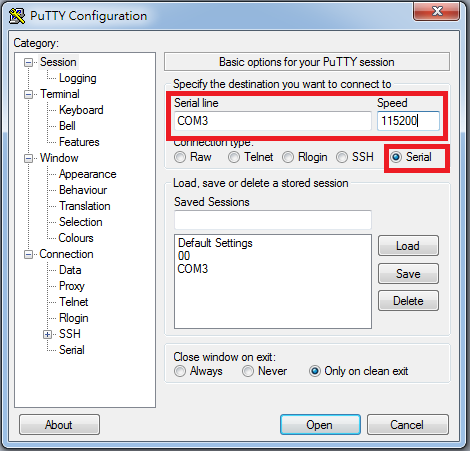
3. 確認連接的 Name Node
$ hive -S -e 'set -v' | grep 'fs.defaultFS'
fs.defaultFS=hdfs://nna:8020
mapreduce.job.hdfs-servers=${fs.defaultFS}
取得大專校院校別學生資料集
1. 下載與處理 大專校院校別學生數檔
$ wget --no-check-certificate https://stats.moe.gov.tw/files/detail/103/103_student.txt
2. 轉換編碼
$ iconv -f UCS-2 -t utf8 103_student.txt -o temp.txt
$ sed 's/\"//g' < temp.txt >student.txt
3. 將 '總計' 欄位資料的 ',' 字元刪除
$ sed 's/,//g' < student.txt >student1.txt
4. 檢視資料
$ head -n 4 student1.txt
大專校院校別學生數
103 學年度 SY2014-2015
學校代碼 學校名稱 日間∕進修別 等級別 總計 男生計 女生計 一年級男生 一年級女生 二年級男生二年級女生 三年級男生 三年級女生 四年級男生 四年級女生 五年級男生 五年級女生 六年級男生六年級女生 七年級男生 七年級女生 延修生男生 延修生女生 縣市名稱 體系別
0001 國立政治大學 D 日 D 博士 973 583 390 117 76 79 62 94 58 98 57 75 53 61 43 59 41 - - 30 臺北市 1 一般
0001 國立政治大學 D 日 M 碩士 3816 1750 2066 626 707 573 683 344 404 207 272 - - - - -- - - 30 臺北市 1 一般
0001 國立政治大學 D 日 B 學士 9639 3711 5928 859 1359 843 1423 857 1394 881 1350 - - - - -- 271 402 30 臺北市 1 一般
啟動 Hive, 建立 student 資料表
1. 啟動 Hive
$ hive -S
2. 建立 student 資料表
hive> CREATE TABLE student (code string, name string, type string, class string, total int) row format delimited fields terminated by '\t' stored as textfile;
3. 載入資料
hive> load data local inpath 'student1.txt' into table student;
4. 顯示資料
hive> select code,name,total from student limit 10;
大專校院校別學生數 NULL
101 學年度 SY2012-2013 NULL
學校代碼 學校名稱 NULL
0001 國立政治大學 973
0001 國立政治大學 3816
0001 國立政治大學 9639
0001 國立政治大學 1625
0002 國立清華大學 1786
0002 國立清華大學 3920
0002 國立清華大學 6280
5. 列印各校總人數
hive> select name,sum(total) from student group by name;
::
長庚科技大學 7595
長榮大學 10474
開南大學 9742
靜宜大學 12249
馬偕醫學院 530
馬偕醫護管理專科學校 4160
高美醫護管理專科學校 850
高苑科技大學 7723
高雄醫學大學 6981
黎明技術學院 4602
龍華科技大學 11254
6. 離開 Hive
hive> quit;
檢視 Hive 運作架構資訊
1. 檢視 Hive MetaData 目錄
$ tree -L 2 metastore_db
metastore_db
├── dbex.lck
├── db.lck
├── log
│ ├── log1.dat
│ ├── log.ctrl
│ └── logmirror.ctrl
├── seg0
│ ├── c101.dat
│ ├── c10.dat
│ ├── c111.dat
::
│ ├── cc0.dat
│ ├── cd1.dat
│ ├── ce1.dat
│ └── cf0.dat
├── service.properties
└── tmp
2. 檢視 Hive 資料表資料
$ hdfs dfs -ls /user/hive/warehouse
Found 1 items
drwxr-xr-x - ds01 biguser 0 2015-11-23 22:09 /user/hive/warehouse/student
Hive 外部資料表
1. 下載 Dataset, 並上載至 Hive 資料倉儲目錄
$ wget http://community.jaspersoft.com/sites/default/files/wiki_attachments/accounts.csv
$ head -n 1 accounts.csv
a69dae1f-b2ee-1257-3895-438dfb8ea964;2005-11-30 19:19:03;2005-11-30 19:19:03;1;beth_id;1;Alpha-Murraiin Communications, Inc;;Manufacturing;Communications;;;5423 Camby Rd.;La Mesa;CA;35890;USA;;;612-555-4878;;;;www.alpha-murraiincommunications,inc.com;;;;;5423 Camby Rd.;La Mesa;CA;35890;USA;0
2. 上載至 Hive 資料倉儲目錄
$ hdfs dfs -mkdir /user/hive/myacc
$ hdfs dfs -put accounts.csv /user/hive/myacc
3. 撰寫 createtbl.q 程序檔, 執行程序檔, 建立 accounts 外部資料表
$ nano createtbl.q
CREATE
EXTERNAL TABLE accounts (
id
STRING,
date_entered STRING,
date_modified STRING,
modified_user_id STRING,
assigned_user_id STRING,
created_by STRING,
name
STRING,
parent_id STRING,
account_type STRING,
industry
STRING,
annual_revenue STRING,
phone_fax STRING,
billing_address_street STRING,
billing_address_city STRING,
billing_address_state STRING,
billing_address_postalcode STRING,
billing_address_country STRING,
description
STRING,
rating
STRING,
phone_office STRING,
phone_alternate STRING,
email1
STRING,
email2
STRING,
website
STRING,
ownership
STRING,
employees
STRING,
sic_code STRING,
ticker_symbol STRING,
shipping_address_street STRING,
shipping_address_city STRING,
shipping_address_state STRING,
shipping_address_postalcode STRING,
shipping_address_country STRING,
deleted
BOOLEAN
)
ROW
FORMAT DELIMITED FIELDS TERMINATED BY '\;'
STORED
AS TEXTFILE LOCATION '/user/hive/myacc';
[註] /user/hive/myacc 是目錄區, 不是資料集名稱
$ hive -S -f createtbl.q
4. 顯示 accounts 資料表的第一筆資料
$ hive -S -e 'select * from accounts limit 1'
a69dae1f-b2ee-1257-3895-438dfb8ea964 2005-11-30 19:19:03 2005-11-30 19:19:03 1 beth_id 1 Alpha-Murraiin Communications, Inc Manufacturing Communications 5423 Camby Rd. La Mesa CA 35890 USA 612-555-4878 www.alpha-murraiincommunications,inc.com 5423 Camby Rd. La Mesa CA 35890 USA NULL
5. 顯示總筆數
$ hive -S -e 'select count(*) from accounts'
1201
6. 刪除 accounts 資料表
$ hive -S -e 'drop table accounts'
accounts 資料表刪除後, 資料檔還是存在 (/user/hive/myacc/accounts.csv)
$ hdfs dfs -ls /user/hive/myacc
Found 1 items
-rw-r--r-- 2 ds01 biguser 357646 2015-11-24 00:37 /user/hive/myacc/accounts.csv
取得美國職棒資料集, 然後上傳到 HDFS
1. 下載 魔球示範資料集
$ wget http://seanlahman.com/files/database/lahman2012-csv.zip
2. 解壓縮 lahman2012-csv.zip
$ unzip lahman2012-csv.zip
3. 上傳美國職棒資料集
$ hdfs dfs -mkdir baseball
$ hdfs dfs -put -f *.csv baseball
$ hdfs dfs -ls baseball
Found 26 items
-rw-r--r-- 2 ds01 biguser 198529 2015-11-23 22:40 baseball/AllstarFull.csv
-rw-r--r-- 2 ds01 biguser 5730747 2015-11-23 22:40 baseball/Appearances.csv
-rw-r--r-- 2 ds01 biguser 7304 2015-11-23 22:40 baseball/AwardsManagers.csv
-rw-r--r-- 2 ds01 biguser 240867 2015-11-23 22:40 baseball/AwardsPlayers.csv
-rw-r--r-- 2 ds01 biguser 16719 2015-11-23 22:40 baseball/AwardsShareManagers.csv
-rw-r--r-- 2 ds01 biguser 220135 2015-11-23 22:40 baseball/AwardsSharePlayers.csv
-rw-r--r-- 2 ds01 biguser 6488747 2015-11-23 22:40 baseball/Batting.csv
-rw-r--r-- 2 ds01 biguser 644669 2015-11-23 22:40 baseball/BattingPost.csv
-rw-r--r-- 2 ds01 biguser 8171830 2015-11-23 22:40 baseball/Fielding.csv
-rw-r--r-- 2 ds01 biguser 298470 2015-11-23 22:40 baseball/FieldingOF.csv
-rw-r--r-- 2 ds01 biguser 573945 2015-11-23 22:40 baseball/FieldingPost.csv
-rw-r--r-- 2 ds01 biguser 175990 2015-11-23 22:40 baseball/HallOfFame.csv
-rw-r--r-- 2 ds01 biguser 130719 2015-11-23 22:40 baseball/Managers.csv
-rw-r--r-- 2 ds01 biguser 3662 2015-11-23 22:40 baseball/ManagersHalf.csv
-rw-r--r-- 2 ds01 biguser 3049250 2015-11-23 22:40 baseball/Master.csv
-rw-r--r-- 2 ds01 biguser 3602473 2015-11-23 22:40 baseball/Pitching.csv
-rw-r--r-- 2 ds01 biguser 381812 2015-11-23 22:40 baseball/PitchingPost.csv
-rw-r--r-- 2 ds01 biguser 700024 2015-11-23 22:40 baseball/Salaries.csv
-rw-r--r-- 2 ds01 biguser 42933 2015-11-23 22:40 baseball/Schools.csv
-rw-r--r-- 2 ds01 biguser 180758 2015-11-23 22:40 baseball/SchoolsPlayers.csv
-rw-r--r-- 2 ds01 biguser 8369 2015-11-23 22:40 baseball/SeriesPost.csv
-rw-r--r-- 2 ds01 biguser 550032 2015-11-23 22:40 baseball/Teams.csv
-rw-r--r-- 2 ds01 biguser 3238 2015-11-23 22:40 baseball/TeamsFranchises.csv
-rw-r--r-- 2 ds01 biguser 1609 2015-11-23 22:40 baseball/TeamsHalf.csv
-rw-r--r-- 2 ds01 biguser 2893177 2015-11-23 22:40 baseball/movies_data.csv
-rw-r--r-- 2 ds01 biguser 12 2015-11-23 22:40 baseball/topyaer.csv
建立 MLB 資料庫及 Master 資料表
1. 建立 MLB 資料庫
$ hive -S -e 'create database MLB'
2. 撰寫 Hive 程序檔
$ nano c_mlb_master.q
create table MLB.Master
( lahmanID INT, playerID STRING, managerID INT, hofID STRING,
birthYear INT, birthMonth INT, birthDay INT, birthCountry STRING,
birthState STRING, birthCity STRING, deathYear INT, deathMonth INT,
deathDay INT, deathCountry STRING, deathState STRING, deathCity STRING,
nameFirst STRING, nameLast STRING, nameNote STRING, nameGiven STRING,
nameNick STRING, weight INT, height INT, bats STRING, throws STRING,
debut STRING, finalGame STRING, college STRING, lahman40ID STRING,
lahman45ID STRING, retroID STRING, holtzID STRING, bbrefID STRING )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
3. 執行 Hive 程序檔, 建立 MLB.Master 資料表
$ hive -S -f c_mlb_master.q
匯入資料到 MLB.Master 資料表
1. 啟動 Hive
$ hive -S
2. 匯入資料
hive> LOAD DATA INPATH "baseball/Master.csv" OVERWRITE INTO TABLE MLB.Master;
3. 選擇 MLB 資料庫
hive> USE MLB;
4. 檢視 Master 資料表內容
hive> SELECT * FROM Master limit 2;
NULL playerID NULL hofID NULL NULL NULL birthCountry birthState birthCity NULL NULLNULL deathCountry deathState deathCity nameFirst nameLast nameNote nameGiven nameNick NULL NULL bats throws debut finalGame college lahman40ID lahman45ID retroID holtzID bbrefID
1 aaronha01 NULL aaronha01h 1934 2 5 USA AL Mobile NULL NULL NULL Hank Aaron Henry Louis "Hammer NULL NULL 180 72 R R 4/13/1954 10/3/1976 aaronha01 aaronha01 aaroh101
5. 列出 MLB 選手總數
hive> SELECT COUNT(*)-1 FROM Master;
181256. 離開 Hive
hive> quit;
建立 MLB.Batting 資料表, 並匯入資料
1. 建立 MLB.Batting 資料表
$ nano c_mlb_batting.q
create table MLB.Batting
( playerID STRING, yearID INT, stint INT, teamID STRING, lgID STRING,
G INT, G_batting INT, AB INT, R INT, H INT, twoB INT, threeB INT, HR INT,
RBI INT, SB INT, CS INT, BB INT, SO INT, IBB INT, HBP INT, SH INT,
SF INT, GIDP INT, G_old INT )
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
$ hive -S -f c_mlb_batting.q
2. 匯入 打擊 資料
$ hive -S -e 'LOAD DATA INPATH "baseball/Batting.csv" OVERWRITE INTO TABLE MLB.Batting'
3. 檢視 打擊 資料
$ hive -S -e 'use MLB; select * from Batting limit 3'
playerID NULL NULL teamID lgID NULL NULL NULL NULL NULL NULL NULL NULL NULL NULLNULL NULL NULL NULL NULL NULL NULL NULL NULL
aardsda01 2004 1 SFN NL 11 11 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 11
aardsda01 2006 1 CHN NL 45 43 2 0 0 0 0 0 0 0 00 0 0 0 1 0 0 45
JOIN 跨表查詢
$ hive -S -e 'use MLB; SELECT A.PlayerID, B.teamID, B.AB, B.R, B.H, B.twoB, B.threeB, B.HR, B.RBI FROM Master A JOIN BATTING B ON A.playerID = B.playerID'
::
zuverge01 DET 4 0 0 0 0 0 0
zuverge01 BAL 23 1 5 1 0 0 0
zuverge01 BAL 17 0 2 0 0 0 2
zuverge01 BAL 23 1 3 0 0 0 0
zuverge01 BAL 9 0 2 0 1 0 2
zuverge01 BAL 0 0 0 0 0 0 0
zwilldu01 CHA 87 7 16 5 0 0 5
zwilldu01 CHF 592 91 185 38 8 16 95
zwilldu01 CHF 548 65 157 32 7 13 94
zwilldu01 CHN 53 4 6 1 0 1 8
資料科學家收工
$ exit